제일기획 강태구 프로(Meta Lab)
Text to Image AI로 콘티 만들어 보기
지난 칼럼에서는 미드저니(MidJourney)를 통해 프롬프트의 기본 구조와 이를 구성하는 각종 수식어구를 알아보았다. 이번 시간은 지난 시간에 대한 일종의 실습이다. 아주 기본적인 프롬프트 작성을 활용한 TVC 콘티 제작 방법 소개할 예정으로, 개념적인 접근이 아닌 실제 광고 회사에서 겪을 수 있는 사례를 통해 생성형 AI를 어떻게 활용할 수 있는지 알아보도록 하겠다.
콘티 스토리를 준비하자
콘티의 스토리를 준비한다. 아래 예시는 실제 콘티가 아닌 이번 글을 위해 임의로 만든 단순 예시다. 콘티 작화가 있는 사례를 가져왔지만, Text to Image인 만큼 상황에 대한 텍스트 설명만 있어도 충분하다.

다만 문제는 그 설명의 ‘자세함’이다. 위에 있는 콘티의 설명은 사실 부족하다. 의상, 표정, 배경, 화질, 각도, 화면 비율 등등에 대한 설명이 없다. 처음 Text를 준비할 때 최대한 디테일하게 준비하는 것이 좋다. 디테일하게 준비해도 AI가 이를 인식하지 못하고 생성하는 경우도 많지만, 최대한 자기 머릿속의 그림이 구체화되어 있어야 그 이미지의 80%라도 구현할 수 있다. 막연히 ‘알아서 나오겠지’라고 기대한다면 실망할 가능성이 크다.
콘티의 디테일을 더하다
콘티의 컷별 디테일을 더한 설명을 다시 정리해 보았다.
S#1
한 남자가 카메라를 보고 손을 흔들고 웃으며 인사한다. 장소는 거실이고
흰 셔츠를 입고 있다, 무언가 말하고 싶어 한다.
S#2
남자가 이탈리안 음식을 만들고 있는 중에 휴대폰으로 전화를 받기 위해 손가락으로 화면을 누른다. 흰 셔츠를 입고 있다, 웃고 있는 표정
S#3
남자가 많은 이탈리안 요리들이 올려져 있는 테이블 앞에서 일어선 채로 휴대폰을 가지고 음식사진을 찍는다. 흰 셔츠를 입고 있다, 웃고 있는 표정
S#4
남자가 휴대폰으로 이탈리안 요리사진을 찍고 있다. 휴대폰 화면이 그림의 대부분을 차지한다, 한낮
프롬프트 형태로 변형하다
어설프긴 하지만 대략적인 디테일 묘사를 해 보았다. 다음에는 이를 프롬프트 형태로 변형한다. 이미지를 형성하는 것에 어떤 특수한 텍스트 입력 방법이 있는 것은 아니다. 위에 있는 글을 영어로 옮겨서 입력하는 것이 기본이다. 실제로 영어로 잘 표현해 입력하기만 해도, 추가적이고 심화된 프롬프트 명령어 없이 의도한 컷을 만들어낼 수 있다. 최근에는 ChatGPT로 번역을 요청하면 잘 정리된 문장으로 번역이 되기에 많은 이들이 [한글 표현 → ChatGPT로 번역 → 미드저니 프롬프트로 입력]하는 수순을 따르고 있다.
이번에도 이런 수순을 따라보자. 위 문장들을 ChatGPT로 번역하면 다음과 같다.
S#1
Ahn Jaehyun waves his hand, smiles, and greets the camera, in a livingroom , wearing white shirts, trying to say something
S#2
While Ahn Jaehyun is preparing Italian dishes, he uses his finger to tap the screen on his mobile phone to answer a call
S#3
Ahn Jaehyun stands in front of a table filled with various Italian dishes and takes food photos with his mobile phone
S#4
He is taking pictures of Italian dishes with his mobile phone, and the phone screen occupies most of the frame
영문을 보고 뭔가 이상함을 느낀 독자들이 있을 것이다. 앞선 한글 텍스트에선 ‘남자’로 적힌 부분이 영문에선 특정 연예인 이름으로 바뀌었다. 프롬프트 제작 때 남자의 얼굴 이미지를 만들기 위해 모델 출신 연예인 이름을 활용하는 경우가 많다. 일반적인 ‘Korean Male’ 이라던가 ‘Asian Male’ 로 표현하면 원하지 않는 인물 이미지가 나올 가능성이 높기 때문이다. 필자의 머릿속에 그려진 남자의 이미지가 이 분에 제일 가깝기에, 이분 이름을 활용했다.
텍스트로 이미지를 생성하다
정리된 텍스트로 이미지들을 생성해 보자.
첫번째 컷이다.
Prompt : Ahn Jaehyun waves his hand, smiles, and greets the camera, in a livingroom , wearing white shirts, trying to say something
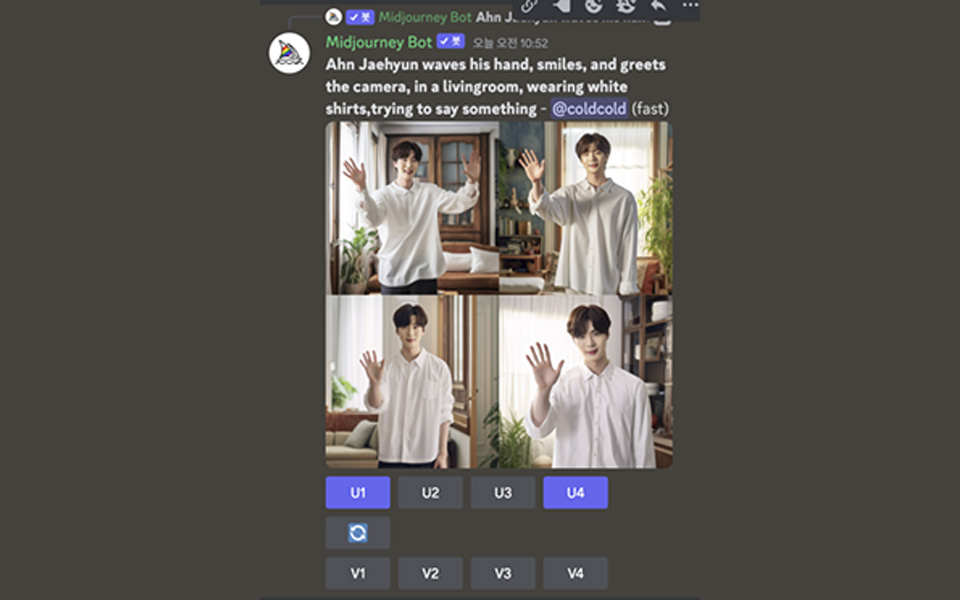
순서는 좌상단부터 우상단, 좌하단, 우하단 순으로 1, 2, 3, 4번이다. 4번을 최종으로 선택했다.. 표정 연출이 디테일해지길 기대하며 [trying to say something]을 추가했는데 누락되었다.
두번째 컷이다.
Prompt : While Ahn Jaehyun is preparing Italian dishes, he uses his finger to tap the screen on his mobile phone to answer a call, wearing a white casual shirts with laughing, extremely detail

예상보다는 결과가 나쁘지 않았지만, 역시 이번에도 [Laughing]이 누락되었다. 또한 이미지를 따로 보여주진 않겠지만 [white casual shirts]가 그냥 티셔츠로 표현되어 재시도하는 경우가 많았다.
세번째 컷이다.
Prompt : Ahn Jaehyun stands in front of a table filled with various Italian dishes and takes food photos with his mobile phone, Ahn Jaehyun is looking at his mobile phone, wearing white shirts with laughing, extremely detail
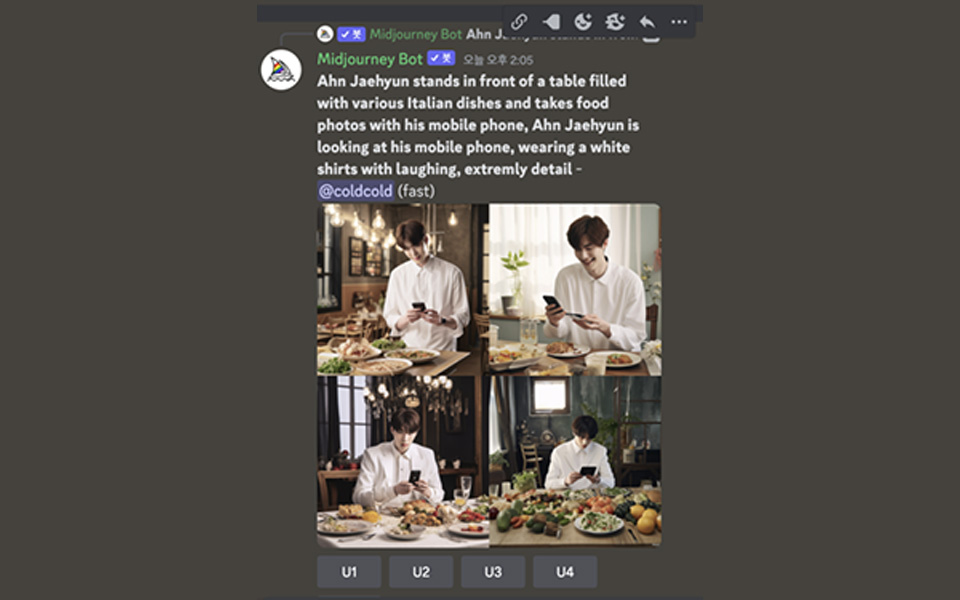
1번 컷이 사실상 의도한 바에 가장 가깝지만 테이블에 놓인 음식과 배경이 앞뒤와 맞지 않아 2번컷을 선택한다. 이전에 모델이 자꾸 휴대폰 이외의 것을 바라보는 컷이 생성되어 프롬프트상에 [looking at his mobile phone]을 추가했고, 배경의 정밀 설정을 추가하기 위해 [extremely detail]을 추가했다.
드디어 마지막 컷이다.
Prompt : He is taking pictures of meat sauce pasta with his mobile phone, and the phone screen occupies most of the frame, extremely detail
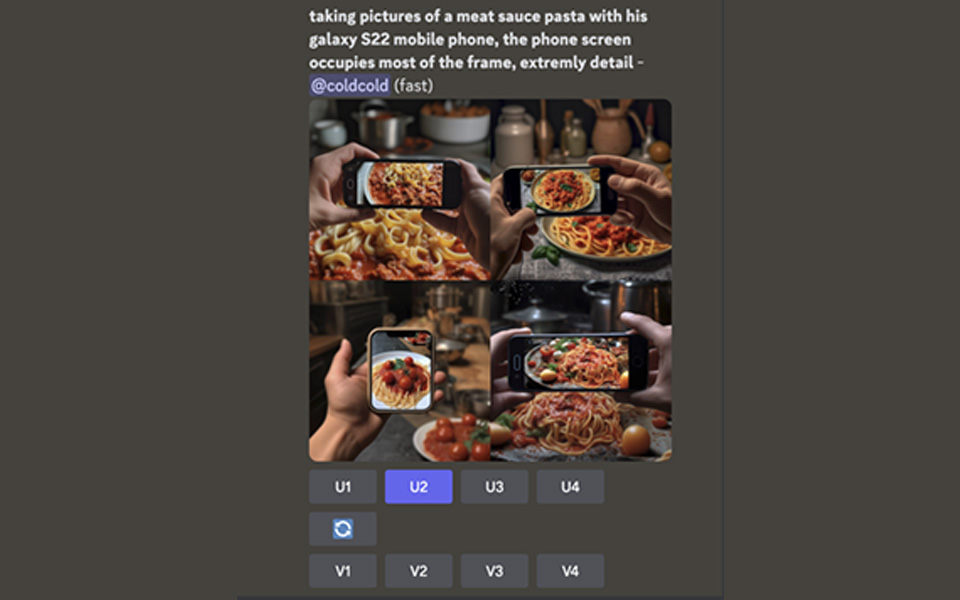
상대적으로 오류가 가장 적었으나, 특정 제품(galaxy)을 명기했음에도 아이폰으로 나오는 점은 결국 해결하지 못했다. 처음 프롬프트였던 [Italian dishes]로 입력할 경우 음식들이 제대로 보이지 않는 경우가 많아 [meat sauce pasta]로 구체화하니 좀 더 명확한 결과물이 나왔다.
이렇게 최종적으로 나오게 된 콘티는 아래 4컷이다.

이렇게 아주 정확하지는 않지만 어느 정도 의도를 전달할 수 있는 형태의 콘티 이미지가 완성되었다. 여러분이 보기에 쓸만해 보이는지 궁금하다.
사실 미드저니로 프롬프트를 이야기하는 것에는 한계가 있다. 미드저니의 대표적 장점은 아티스틱한 스타일 연출(예를 들면 피카소 스타일, 일본 애니메이션 스타일 등)이다. 화면에 지시하지 않는 배경이나 소품 등 다양한 요소를 AI가 ‘알아서 잘’ 구성해 준다는 점이 강점이다. 하지만 반대로 내가 ‘의도한’ 캐릭터와 구도 등을 만드는 것이 어렵다는 단점 또한 있다.
그러다 보니 ‘의도한’ 것들이 많이 담기는 프롬프트일수록 AI가 무시하는 것이 많아진다. 실제로 생성형 AI를 통해 원하는 만큼 정확한 이미지를 뽑아내는데 여러 이유로 시간이 소요되기에 많은 분들이 후보정이나 생성형 AI간의 결합을 통해(각 부분을 뽑아서 나중에 합성) 원하는 이미지를 만들어 내곤 한다.
그래서 현재는 다양한 모델을 통해 내가 ‘프롬프팅’과 여러 ‘변수’(파라미터)를 활용해 ‘의도한’ 방향으로 ‘생성된’ 이미지를 얻어내는 것으로 Text to Image 모델 연구가 이루어지고 있으며, 이중 최근 가장 주목받는 것이 Diffusion 모델을 활용한 방법들이다. 다음 시간에는 Diffusion 모델을 활용한 Text to Image 생성에 대해 소개해보도록 하겠다.
제일기획 강태구 프로(Meta Lab)